
티스토리 뷰
https://www.youtube.com/watch?v=exgO1LFl9x8&list=PLMsa_0kAjjrd8hYYCwbAuDsXZmHpqHvlV&index=5
<RPA 구성 내용>
| 엑셀 자동화 | 데스크탑 자동화 | 웹 자동화 | 이메일 자동화 |
| - 데이터 / 수식 - 셀 편집 - 스타일 - 차트 - 이미지 - 저장 / 불러오기 |
- UI 자동화 - 좌표, 픽셀, 이미지 - 마우스 - 키보드 - 윈도우 관리 - 파일 시스템 (파일, 폴더 다루는 법) - 로그 (로그 남기는 법) |
- 페이지 이동 - HTML & XPath - 다양한 Element 처리 (radio 버튼, 체크 박스 선택 등) - 동적 페이지 - 특정 영역 스크롤 - 프레임 & 창 전환 - 브라우저 핸들 관리 |
- 메일 발신 - 참조, 비밀참조 - 첨부 파일 - 메일 수신 - 메일 상제 정보 - 메일 필터링 |
1. 엑셀 자동화
※ 1~20)까지 수행하는 코드는 모드 1) 파일 만들기에서 생성한 파일로 수행됩니다.
1) 파일 만들기
VSCode terminal에 아래 코드를 입력해 라이브러리를 설치해줍니다.
pip install openpyxl
다음으로, 업무 자동화를 위한 파일을 만들기 위한 코드입니다.
# 1. 파일 만들기
from openpyxl import Workbook
wb = Workbook() # 새 워크북 생성
ws = wb.active # 현재 활성화된 sheet를 가져옴
ws.title = "NadoSheet" # sheet의 이름을 변경
wb.save("sample.xlsx") # 파일 저장
wb.close() # 파일 닫음
2) 시트
시트 생성, 시트 이름 변경, 시트 탭 색상 변경, 시트 복사를 수행합니다.
from openpyxl import Workbook
wb = Workbook()
# ws = wb.active # 현재 활성화된 sheet를 가져옴
ws = wb.create_sheet() # 새로운 sheet를 생성
ws.title = "MySheet" # sheet 이름 변경
ws.sheet_properties.tabColor = "89c3d7"
# Sheet, MySheet, YourSheet
ws1 = wb.create_sheet("YourSheet") # 주어진 이름으로 sheet 생성
ws2 = wb.create_sheet("NewSheet", 2) # 2번째 index에 sheet 생성
new_ws = wb["NewSheet"] # Dict 형태로 sheet에 접근 가능
print(wb.sheetnames) # 모든 sheet 이름 확인
# Sheet 복사
new_ws["A1"] = "Test"
target = wb.copy_worksheet(new_ws)
target.title = "Copied Sheet"
wb.save("sample.xlsx")
3) 셀
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
ws.titile = "NadoSheet"
# A1 셀에 1 이라는 값을 입력
ws["A1"] = 1
ws["A2"] = 2
ws["A3"] = 3
ws["B1"] = 4
ws["B2"] = 5
ws["B3"] = 6
print(ws["A1"]) # A1 셀의 정보를 출력
print(ws["A1"].value)
print(ws["A10"].value) # 값이 없을 땐 None을 출력
# row = 1, 2, 3, ...
# column = A(1), B(2), C(3), ...
print(ws.cell(row=1, column=1).value)
print(ws.cell(row=1, column=2).value)
c = ws.cell(column=3, row=1, value=10) # ws["C1"].value = 10
print(c.value)
from random import *
# 반복문을 이용해서 랜덤 숫자 채우기
index = 1
for x in range(1,11): # 10개 row
for y in range(1,11): # 10개 column
ws.cell(row=x,column=y, value=index) # 0~100 사이의 숫자'
index += 1 # (index에 1~100의 숫자를 입력함으로써 row, column 어떤 순서로 이루어지는지 확인할 수 있음)
wb.save("sample.xlsx")
4) 파일 열기
기존에 생성된 파일을 VSCode 에서 열고, cell 안의 데이터를 확인하는 과정입니다.
from openpyxl import load_workbook
wb = load_workbook("sample.xlsx") # sample.xlsx 파일에서 wb을 불러옴
ws = wb.active # 활성화된 Sheet
# # cell 데이터 불러오기
# for x in range(1,11):
# for y in range(1,11):
# print(ws.cell(row=x, column=y).value, end=" ") # 1 2 3 4 ..
# print()
# cell 갯수를 모를 때
for x in range(1, ws.max_row+1):
for y in range(1, ws.max_column+1):
print(ws.cell(row=x, column=y).value, end=" ") # 1 2 3 4 ..
print()
5) 셀 영역 1
데이터의 특정 셀 범위를 지정해서 값을 불러오는 방법
# 셀 영역 1
# 셀의 범위를 지정해서 가져오기
from openpyxl import Workbook
from random import *
wb = Workbook()
ws = wb.active
# 1줄씩 데이터 넣기
ws.append(["번호","영어","수학"])
for i in range(1, 11): # 10개 데이터 넣기
ws.append([i, randint(0,100), randint(0,100)])
col_B = ws["B"] # 영어 column 만 가지고 오기
# print(col_B)
# for cell in col_B:
# print(cell.value)
col_range = ws["B:C"] # 영어, 수학 column 함께 가지고 오기
# for cols in col_range:
# for cell in cols:
# print(cell.value)
row_title = ws[1] # 1번째 row만 가져 오기
# for cell in row_title:
# print(cell.value)
# row_range = ws[2:6] # 1번째 줄인 title을 제외하고 2번째 줄에서 6번째 줄까지 가지고 오기
# for rows in row_range:
# for cell in rows:
# print(cell.value, end=" ")
# print()
# 각 cell에 대한 정보를 확인하고자 할 때 사용
from openpyxl.utils.cell import coordinate_from_string
row_range = ws[2:ws.max_row] # 2번째 줄부터 마지막 줄까지
for rows in row_range:
for cell in rows:
# print(cell.value, end=" ")
# print(cell.coordinate, end=" ")
xy = coordinate_from_string(cell.coordinate) # tuple 형태 ('문자', 숫자)
# print(xy, end=" ")
print([xy[0]], end="") # A
print([xy[1]], end=" ") # 1
print()
wb.save("sample.xlsx")
6) 셀 영역 2
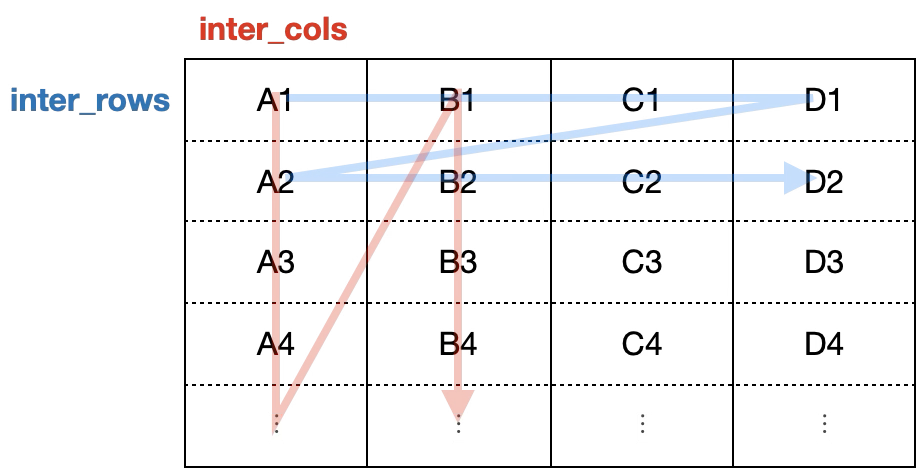
# 셀 영역 2
# 전체 row에 대한 정보를 가져오기
print(ws.rows)
print(tuple(ws.rows)) # 모든 줄에 대해서 묶어서 tuple로 나눠줌
for row in tuple(ws.rows):
print(row[1].value)
# 전체 column에 대한 정보를 가져오기
print(tuple(ws.columns)) # 모든 줄에 대해서 묶어서 tuple로 나눠줌
for column in tuple(ws.columns):
print(column[0].value)
for row in ws.iter_rows(): # 전체 row에 대해서 반복하며 가져오기
print(row[1].value)
for column in ws.iter_cols(): # 전체 column에 대해서 반복하며 가져오기
print(column[0].value)
# 범위를 지정해줄 수 있다는 게 장점
# 즉,
for row in ws.iter_rows(min_row=1, max_row=5):
print(row[2].value)
# 2번째 줄부터 11번째 줄까지, 2번째 열부터 3번째 열까지
for row in ws.iter_rows(min_row=2, max_row=11, min_col=2, max_col=3):
print(row[0].value, row[1].value) # 수학, 영어
for col in ws.iter_cols(min_row=1, max_row=5, min_col=1, max_col=3):
print(col[0].value, col[1].value) # 수학, 영어
# iter_rows, inter_cols의 옵션은 최소가 기본값임
7) 찾기
# 찾기
# 값에서 조건에 맞게 추출하는 방법
from openpyxl import load_workbook
wb = load_workbook("sample.xlsx")
ws = wb.active
for row in ws.iter_rows(min_row=2):
# 번호, 영어, 수학
if int(row[1].value) > 80:
print(row[0].value, "번 학생은 영어 천재")
# 영어 과목이 사실은 컴퓨터 과목이었을 경우
# 데이터 값을 찾아서 바꿔줌
for row in ws.iter_rows(max_row=1):
for cell in row:
if cell.value == "영어":
cell.value = "컴퓨터"
wb.save("sample_modified.xlsx")
8) 삭제
from openpyxl import load_workbook
wb = load_workbook("sample.xlsx")
ws = wb.active
# ws.delete_rows(8) # 8번째 줄에 있는 7번 학생 데이터 삭제
# ws.delete_rows(8,3) # 8번째 줄부터 총 3줄 삭제
# wb.save("sample_delete_row.xlsx")
# ws.delete_cols(2) # 2번째 열 (B) 삭제
ws.delete_cols(2,2) # 2번째 열로부터 총 2개 열 삭제
wb.save("sample_delete_col.xlsx")
9) 이동
from openpyxl import load_workbook
wb = load_workbook("sample.xlsx")
ws = wb.active
# 번호 영어 수학
# 번호 (국어) 영어 수학
# ws.move_range("B1:C11", rows=0, cols=1) # 한 열을 오른쪽으로 한 칸 이동
# ws["B1"].value = "국어" # B1 셀에 '국어' 입력
# 번호 영어 수학
ws.move_range("C1:C11", rows=5, cols=-1) # 영어 자리 5번째 열부터 수학 열 이동
wb.save("sample_korean.xlsx")
10) 차트
더 자세한 내용은 openpyxl 사이트에서 확인할 수 있습니다.
https://openpyxl.readthedocs.io/en/stable/charts/introduction.html#charts
from openpyxl import load_workbook
wb = load_workbook("sample.xlsx")
ws = wb.active
from openpyxl.chart import BarChart, Reference, LineChart
# 처음에는 value를 설정해 주어야 함 (어떤 데이터를 차트로 만들지에 대한 정의)
# B2:C11 까지의 데이터를 차트로 생성
# bar_value = Reference(ws, min_row=2, max_row=11, min_col=2, max_col=3)
# bar_chart = BarChart() # 차트 종류 설정 (Bar, Line, Pie, ..)
# bar_chart.add_data(bar_value) # 차트 데이터 추가
# ws.add_chart(bar_chart, "E1") # 차트 넣을 위치 정의
# B1:C11 까지의 데이터
line_value = Reference(ws, min_row=1, max_row=11, min_col=2, max_col=3)
line_chart = LineChart()
line_chart.add_data(line_value, titles_from_data=True) # 계열 > 영어, 수학 (제목에서 가져옴)
line_chart.title = "성적표"
line_chart.style = 10 # 미리 정의된 스타일을 적용, 사용자가 개별 지정
line_chart.y_axis.title = "점수" # Y축의 제목
line_chart.x_axis.title = "번호" # X축의 제목
ws.add_chart(line_chart, "E1")
wb.save("smaple_chart.xlsx")
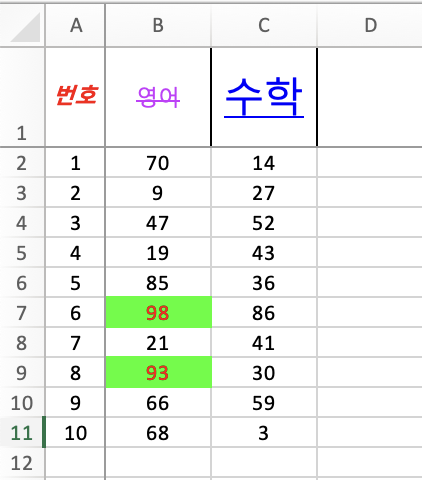
11) 셀 스타일
셀 높이, 너비, 글꼴, 색상, 크기 등 적용
from openpyxl.styles import Font, Border, Side
from openpyxl import load_workbook
wb = load_workbook("sample.xlsx")
ws = wb.active
# 번호, 영어, 수학
a1 = ws["A1"] # 번호
b1 = ws["B1"] # 영어
c1 = ws["C1"] # 수학
# A 열의 너비를 5로 설정
ws.column_dimensions["A"].width = 5
# 1 행의 높이를 50으로 설정
ws.row_dimensions[1].height = 50
# 스타일 적용
a1.font = Font(color="FF0000", italic=True, bold=True) # 글자 색은 빨갛게, 이탤릭, 두껍게 적용
b1.font = Font(color="CC33FF", name="Arial", strike=True) # 폰트를 Arial로 설정, 취소선 적용
c1.font = Font(color="0000FF", size=20, underline='single') # 글자 크기를 20으로, 밑줄 적용
# 테두리 적용
thin_border = Border(left=Side(style="thin"), right=Side(style="thin"), top=Side(style="thin"), bottom=Side(style="thin"))
a1.border = thin_border
b1.border = thin_border
c1.border = thin_border
wb.save("sample_style.xlsx")
12) 수식
엑셀에서와 동일하게 셀의 수식을 설정할 수 있음
import datetime
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
ws["A1"] = datetime.datetime.today() # 오늘 날짜 정보
ws["A2"] = "=SUM(1, 2, 3)" # 1 + 2 + 3 = 6
ws["A3"] = "=AVERAGE(1, 2, 3)" # 2 (평균)
ws["A4"] = 10
ws["A5"] = 20
ws["A6"] = "=SUM(A4:A5)" # 30
wb.save("sample_formula.xlsx")
13. 수식 (데이터 전용)
from openpyxl import load_workbook
# wb = load_workbook("sample_formula.xlsx")
# ws = wb.active
# # 수식 그대로 가져오고 있음
# for row in ws.values:
# for cell in row:
# print(cell)
wb = load_workbook("sample_formula.xlsx", data_only=True) # 실제 데이터 가져오는 옵션
ws = wb.active
# 수식 그대로 가져오고 있음
# evaluate 되지 않은 상태의 데이터는 None 이라고 표시
for row in ws.values:
for cell in row:
print(cell)
14) 셀 병합
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
# 병합하기
ws.merge_cells("B2:D2") # B2부터 D2까지 합치겠음
ws["B2"].value = "Merged Cell"
wb.save("sample_merge.xlsx")
# 병합 해제하기
from openpyxl import load_workbook
wb = load_workbook("sample_merge.xlsx")
ws = wb.active
# B2:D2 병합되어 있던 셀을 해제
ws.unmerge_cells("B2:D2")
wb.save("sample_unmerge.xlsx")
15) 이미지 삽입
from openpyxl import Workbook
from openpyxl.drawing.image import Image
wb = Workbook()
ws = wb.active
img = Image("img.png")
# C3 위치에 img.png 파일의 이미지를 삽입
ws.add_image(img, "C3")
wb.save("sample_image.xlsx")
# ImportError: You must install Pillow to fetch image objects
# pip install Pillow만약 ImportError가 발생한 경우 terminal에서 Pillow 패키지를 설치해줍니다.
16) Quiz
# Quiz) 여러분은 나도대학의 컴퓨터과 교수님입니다.
# 여러분이 가르치는 과목의 점수 비중은 다음과 같습니다.
# - 출석 : 10
# - 퀴즈1 : 10
# - 퀴즈2 : 10
# - 중간고사 : 20
# - 기말고사 : 20
# - 프로젝트 : 20
# ---------------
# - 총합 : 100
# 마지막 수업을 모두 마치고 이번 학기 학생들의 최송 성적을 검토하는 과정에서
# 퀴즈2 문제에 오류를 발견하여 모두 만점 처리를 하기로 하였습니다.
# 현재까지 작성된 최종 성적 데이터를 기준으로 아래와 같이 수정하시오.
# 1. 퀴즈2 점수를 10으로 수정
# 2. H열에 총점(SUM이용), I열에 성적 정보 추가
# - 총점 90점 이상 A, 80점 이상 B, 70점 이상 C, 나머지 D
# 3. 출석이 5 미만인 학생은 총점 상관없이 F
더보기
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
# 현재까지 작성된 최종 성적 데이터를 넣기
ws.append(("학번", "출석", "퀴즈1", "퀴즈2", "중간고사", "기말고사", "프로젝트"))
scores = [
(1,10,8,5,14,26,12),
(2,7,3,7,15,24,18),
(3,9,5,8,8,12,4),
(4,7,8,7,17,21,18),
(5,7,8,7,16,25,15),
(6,3,5,8,8,17,0),
(7,4,9,10,16,27,18),
(8,6,6,6,15,19,17),
(9,10,10,9,19,30,19),
(10,9,8,8,20,25,20)
] # 10개의 tuple을 가진 하나의 리스트
for s in scores: # 기존 성적 데이터 넣기
ws.append(s)
# 1. 퀴즈2 점수를 10으로 수정
# enumerate() 함수는 함수는 인덱스와 원소로 이루어진 튜플(tuple)을 만들어 준다.
for idx, cell in enumerate(ws["D"]):
if idx == 0: # 제목인 경우 skip
continue
cell.value = 10
# 2. H열에 총점(SUM이용), I열에 성적 정보 추가
ws["H1"] = "총점"
ws["I1"] = "성적"
for idx, score in enumerate(scores, start=2):
sum_val = sum(score[1:]) - score[3] + 10 # 총점
ws.cell(row=idx, column=8).value = "=SUM(B{}:G{})".format(idx,idx)
# SUM(B2:G2)
# SUM(B3:G3) ...
# - 총점 90점 이상 A, 80점 이상 B, 70점 이상 C, 나머지 D
grade = None
if sum_val >= 90:
grade = "A"
elif sum_val >= 80:
grade= "B"
elif sum_val >= 70:
grade= "C"
else:
grade="D"
# 3. 출석이 5 미만인 학생은 총점 상관없이 F
if score[1] < 5:
grade = "F"
ws.cell(row=idx, column=9).value = grade # I열에 성적 정보 추가
wb.save("scores.xlsx")'문과생이 이해하는 개발의 길 🚀 > Python' 카테고리의 다른 글
| [파이썬 코딩 무료 강의 (기본편)]: 02. 제어문 (if, for, while) (0) | 2025.01.29 |
|---|---|
| [파이썬 코딩 무료 강의 (기본편)]: 01. 자료 구조 (리스트, 사전, 튜플, 집합) (1) | 2025.01.29 |
| [파이썬 코딩 무료 강의 (기본편)]: 00. 환경설정 (0) | 2025.01.28 |